ABOUT ME
My research focuses on methods, applications, and ethics of Computational Modeling in Human-Computer Interaction (HCI). Although both qualitative and quantitative empirical methods play an important role in my work, I specialize in creating and using computational modeling approaches to study people. However, the complex computational models of human behavior that I create are rarely (if ever) inherently explainable to and interpretable by a broader audience of relevant stakeholders (e.g., domain experts, consumers). Thus, I have taken a keen interest in developing methods to explain the decisions of such models—and other Artificial Intelligence (AI)—to end-users who are not math-savvy computer scientists. Furthermore, the computational models that I create could have a negative impact on the society (e.g., they can be appropriated into surveillance technology). Therefore, I study ethical considerations for responsible creation and use of such computational technology (in particular methods for detecting and countering untrustworthy AI).
My work has been recognized with an NSF CAREER award, and best paper and honorable mention awards at premier HCI conferences.
Before joining the University of Michigan, I received my Ph.D. degree from the Human-Computer Interaction Institute (HCII) at Carnegie Mellon University, and my B.Sc. and M.Sc. degrees from the University of Toronto.
For more information, see my Curriculum Vitae (CV).
ADVISEES
PhD Candidates
PhD Students
- Tsedeniya Amare
- Jaewoong Choi
Masters Students
Undergraduate students
- Trisha Dani
- Tess Eschebach
- Matthew Conrad
- Tavanya Seth
- Rui Nie
- Tavanya Seth
- Zhe Chen
- Ananya Kasi
ALUMNI
Masters Students
- Xincheng Huang (then PhD student at UBC)
- Suraj Kiran Raman (then Research Scientist at Schlumberger)
- Aditya Ramesh (then Applied Researcher at eBay)
- Zhuoran "Jim" Yang
- Yujian Liu (then Ph.D. student at UCSB)
Undergraduate Students
- Caitlin Henning
- Yuan Xu
- Sabrina Tobar Thommel
- Antara Gandhi
- Jiankai Pu (then MS at the UofT)
- Yucen Sun (then MS at Columbia University)
- Enhao Zhao (then Ph.D. at the UW)
- Nan Liu (then MS at UIUC)
- Elise Minto
- Zhipeng Yan
- Alvin Hermans
- Joshua Spalter
- Yu Wang
- Ponette Rubio
- Keylonnie Miller (then Facebook)
- Alice Liu
- Renee Li
- Sam Mikell
Visitors
- Tahera Hossain (Visiting PhD student, Kyushu Institute of Technology, Japan)
- Tsedenia Solomon Amare (AURA visiting Undergraduate student)
- Bruktawit Amare (AURA visiting Undergraduate student)
- Daniel Ramirez (Undergraduate Summer Research Intern, Universidad de Monterrey)
- Shareni Ortega (Undergraduate Summer Research Intern, Universidad de Monterrey)
- Shruti Srinidhi (Undergraduate Summer Research Intern, Carnegie Mellon University)
TEACHING
EECS 593 - Human-Computer Interaction (3 credits)
Winter 2020, Fall 2020, Fall 2021, Fall 2022, Fall 2023
Principles (e.g., human-centered systems design, usability, accessibility) and methods (e.g., requirements gathering, functional prototyping, user study evaluation) of technical Human-Computer Interaction (HCI) research. Survey of HCI research threads including Human-AI Interaction, Social Computing, Behavior Modeling, Education Technologies. Group assignments give students exposure to HCI research methods. Prerequisites: Graduate standing; or permission from instructor.
EECS 493 - User Interface Development (4 credits)
Winter 2021, Winter 2022, Winter 2023
Concepts and techniques for designing computer system user interfaces to be easy to learn and use, with an introduction to their implementation. Task analysis, design of functionality, display and interaction design, and usability evaluation. Interface programming using an object-oriented application framework. Fluency in a standard object-oriented programming language is assumed. Prerequisites: EECS 281 or graduate standing in CSE. Minimum grade of “C” required for enforced prerequisite.
EECS 598 - Computational Modeling in Human-Computer Interaction (3 credits)
Fall 2018, Fall 2019
This seminar course will review current computational approaches to describe, simulate, and predict human behavior from empirical behavior traces data. It will contrast computational modeling with other methodologies to understand human behavior and compare computational modeling with existing behavior modeling methodologies in Human-Computer Interaction (HCI). Short assignments will give students exposure to some of the cutting-edge methods, while the final project will give them an opportunity to push the boundaries of computational modeling in HCI by modeling behaviors of their choice from an existing data set. Prerequisites: Graduate standing; or permission from instructor.
EECS 498 - Modeling Human Behavior (4 credits)
Winter 2019
This course will teach students methods to track, collect, and express human behavior data as computational models of behavior. The course will have a particular focus on computational approaches to describe, simulate, and predict human behavior from empirical behavior traces data. It will contrast computational modeling with other methodologies to understand human behavior and compare computational modeling with existing behavior modeling methodologies in Human-Computer Interaction (HCI). Short individual assignments will give students exposure to existing modeling methods in HCI. Large, group-based final project will give students an opportunity to push the boundaries of computational modeling in HCI by modeling behaviors of their choice from an existing data set to design and implement a novel Computational Modeling system from scratch. Prerequisites: EECS 281 and (EECS 370 or EECS 376) or permission from instructor.
SELECT RECENT PUBLICATIONS (for a complete list see my Google Scholar and dblp pages)
Human Behavior Modeling and Computational Interaction
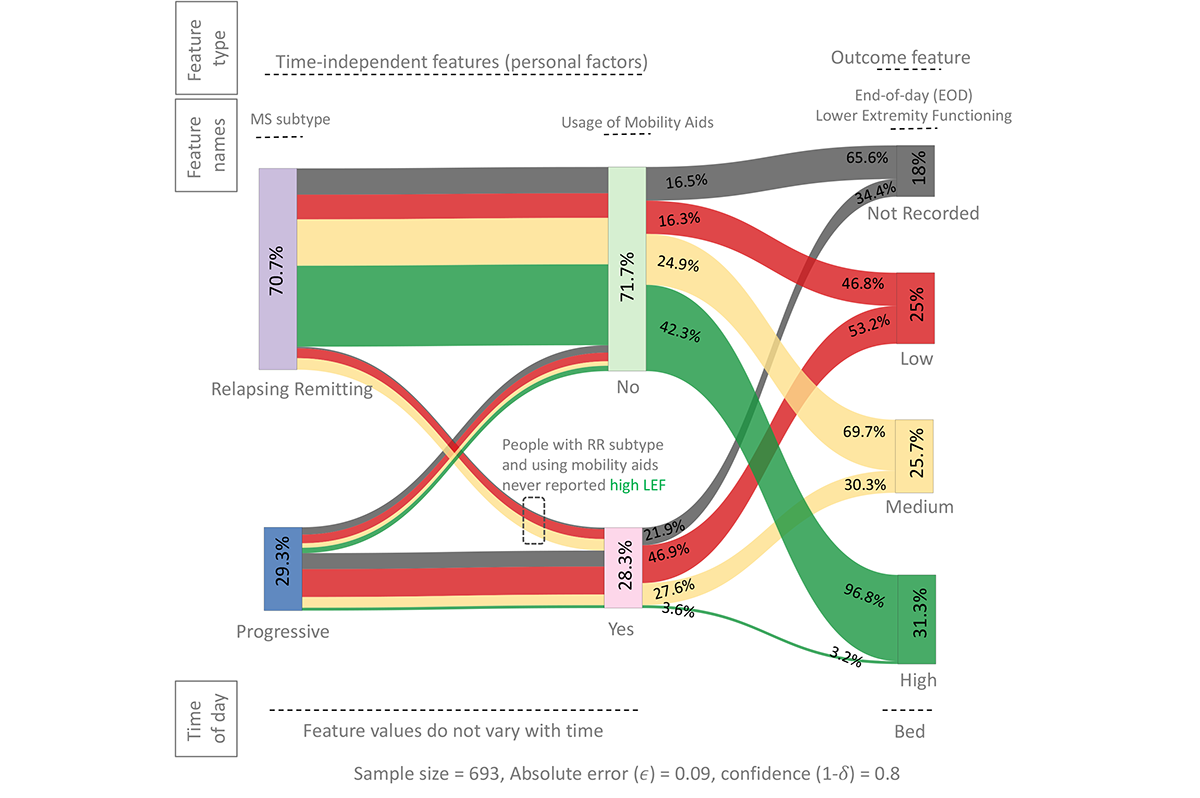
Behavior Modeling Approach for Forecasting Physical Functioning of People with Multiple Sclerosis
Anindya Das Antar, Anna Kratz, and Nikola Banovic
PACM IMWUT 7, 1, Article 7 (March 2023), 29 pages.
Forecasting physical functioning of people with Multiple Sclerosis (MS) can inform timely clinical interventions and accurate "day planning" to improve their well-being. However, people's physical functioning often remains unchecked in between infrequent clinical visits, leading to numerous negative healthcare outcomes. Existing Machine Learning (ML) models trained on in-situ data collected outside of clinical settings (e.g., in people's homes) predict which people are currently experiencing low functioning. However, they do not forecast if and when people's symptoms and behaviors will negatively impact their functioning in the future. Here, we present a computational behavior model that formalizes clinical knowledge about MS to forecast people's end-of-day physical functioning in advance to support timely interventions. Our model outperformed existing ML baselines in a series of quantitative validation experiments. We showed that our model captured clinical knowledge about MS using qualitative visual model exploration in different "what-if" scenarios. Our work enables future behavior-aware interfaces that deliver just-in-time clinical interventions and aid in "day planning" and "activity pacing".
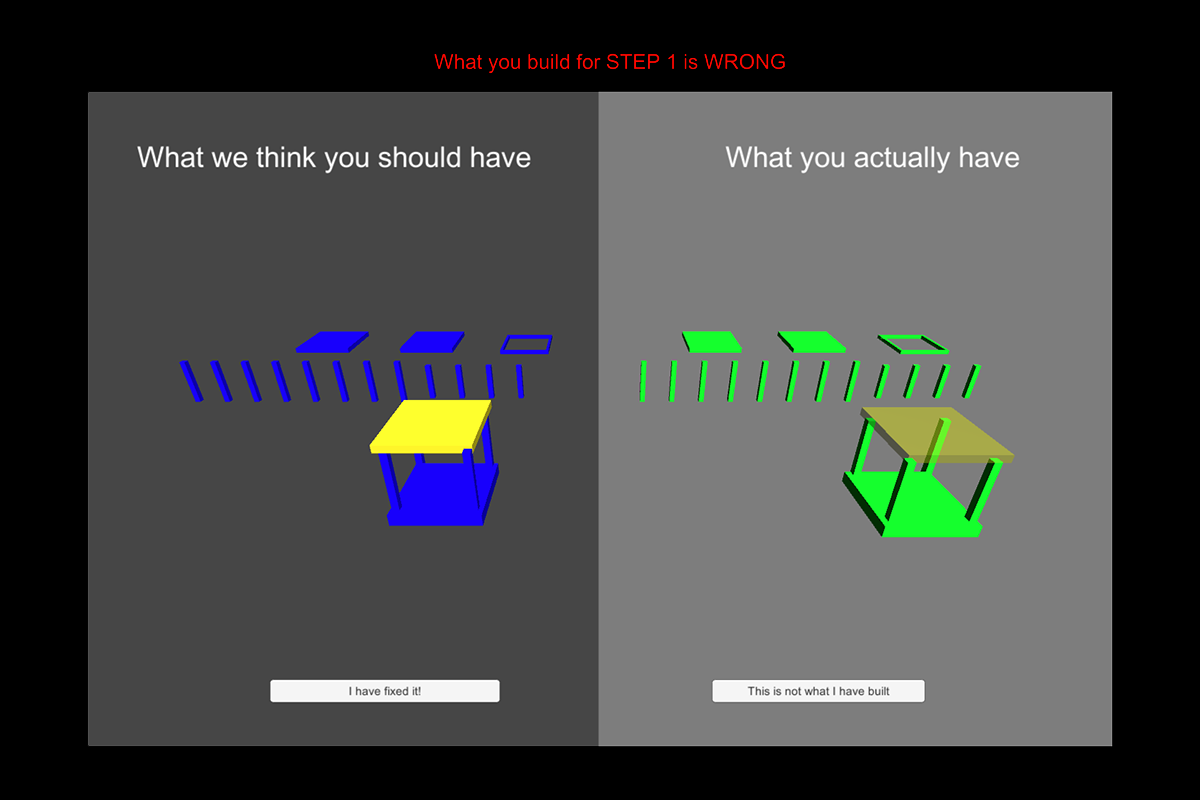
StructureSense: Inferring Constructive Assembly Structures from User Behaviors
Xincheng Huang, Keylonnie L. Miller, Alanson P. Sample, and Nikola Banovic
PACM IMWUT 6, 4, Article 204 (December 2022), 25 pages.
Recent advancements in object-tracking technologies can turn mundane constructive assemblies into Tangible User Interfaces (TUI) media. Users rely on instructions or their own creativity to build both permanent and temporary structures out of such objects. However, most existing object-tracking technologies focus on tracking structures as monoliths, making it impossible to infer and track the user's assembly process and the resulting structures. Technologies that can track the assembly process often rely on specially fabricated assemblies, limiting the types of objects and structures they can track. Here, we present StructureSense, a tracking system based on passive UHF-RFID sensing that infers constructive assembly structures from object motion. We illustrated StructureSense in two use cases (as guided instructions and authoring tool) on two different constructive sets (wooden lamp and Jumbo Blocks), and evaluated system performance and usability. Our results showed the feasibility of using StructureSense to track mundane constructive assembly structures.
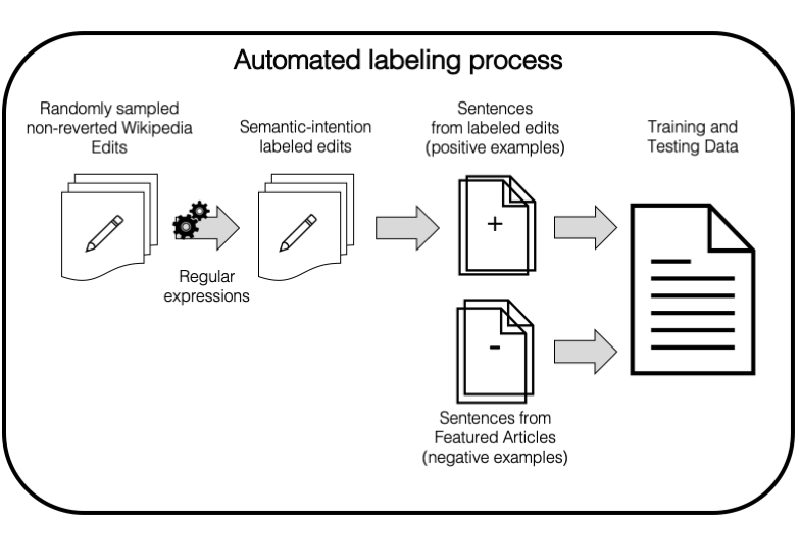
Automatically Labeling Low Quality Content on Wikipedia By Leveraging Patterns in Editing Behaviors
Sumit Asthana, Sabrina Tobar Thommel, Aaron Lee Halfaker, and Nikola Banovic
PACM HCI 5, CSCW2, Article 359 (October 2021). ACM, New York, NY, USA, 23 pages.
Wikipedia articles aim to be definitive sources of encyclopedic content. Yet, only 0.6% of Wikipedia articles have high quality according to its quality scale due to insufficient number of Wikipedia editors and enormous number of articles. Supervised Machine Learning (ML) quality improvement approaches that can automatically identify and fix content issues rely on manual labels of individual Wikipedia sentence quality. However, current labeling approaches are tedious and produce noisy labels. Here, we propose an automated labeling approach that identifies the semantic category (e.g., adding citations, clarifications) of historic Wikipedia edits and uses the modified sentences prior to the edit as examples that require that semantic improvement. Highest-rated article sentences are examples that no longer need semantic improvements. We show that training existing sentence quality classification algorithms on our labels improves their performance compared to training them on existing labels. Our work shows that editing behaviors of Wikipedia editors provide better labels than labels generated by crowdworkers who lack the context to make judgments that the editors would agree with.
Explainability and Interpretability through Interaction
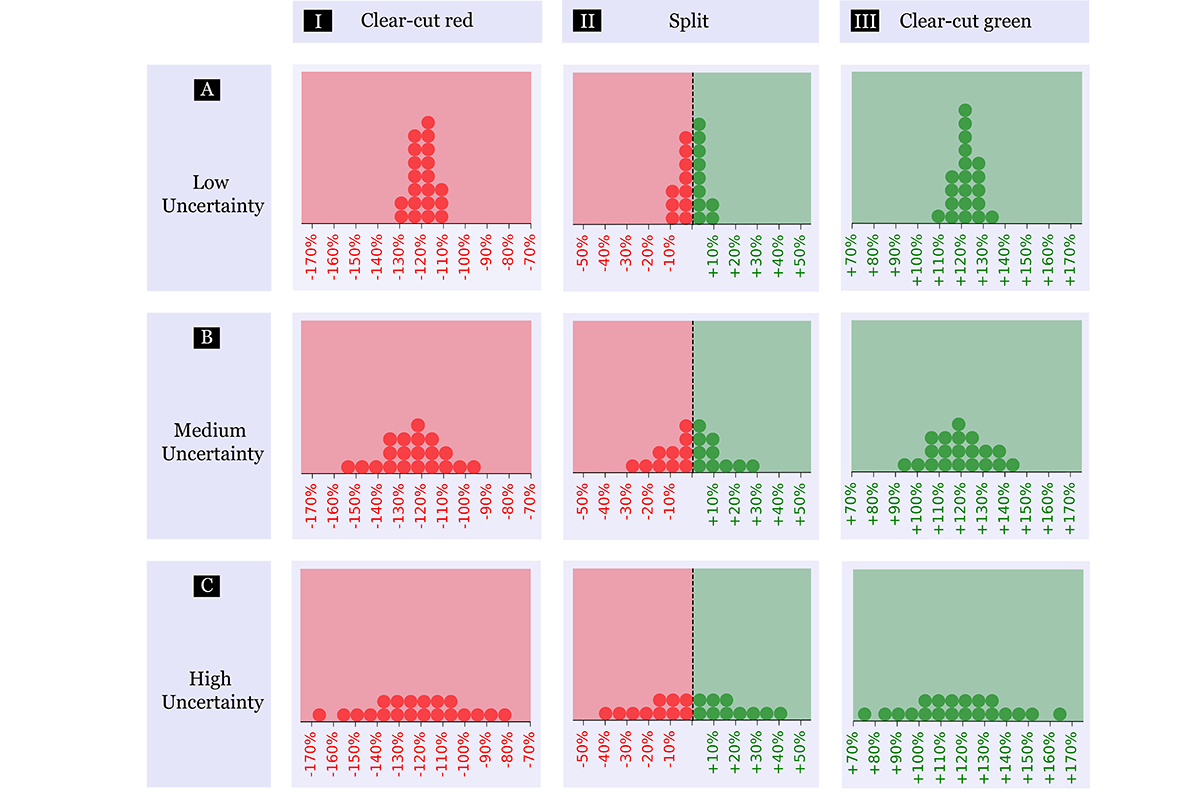
Understanding Uncertainty: How Lay Decision-makers Perceive and Interpret Uncertainty in Human-AI Decision Making
Snehal Prabhudesai, Leyao Yang, Sumit Asthana, Xun Huan, Q. Vera Liao, and Nikola Banovic
In Proc. IUI '23. ACM, New York, NY, USA, 379–396.
Decision Support Systems (DSS) based on Machine Learning (ML) often aim to assist lay decision-makers, who are not math-savvy, in making high-stakes decisions. However, existing ML-based DSS are not always transparent about the probabilistic nature of ML predictions and how uncertain each prediction is. This lack of transparency could give lay decision-makers a false sense of reliability. Growing calls for AI transparency have led to increasing efforts to quantify and communicate model uncertainty. However, there are still gaps in knowledge regarding how and why the decision-makers utilize ML uncertainty information in their decision process. Here, we conducted a qualitative, think-aloud user study with 17 lay decision-makers who interacted with three different DSS: 1) interactive visualization, 2) DSS based on an ML model that provides predictions without uncertainty information, and 3) the same DSS with uncertainty information. Our qualitative analysis found that communicating uncertainty about ML predictions forced participants to slow down and think analytically about their decisions. This in turn made participants more vigilant, resulting in reduction in over-reliance on ML-based DSS. Our work contributes empirical knowledge on how lay decision-makers perceive, interpret, and make use of uncertainty information when interacting with DSS. Such foundational knowledge informs the design of future ML-based DSS that embrace transparent uncertainty communication.

Method for Exploring Generative Adversarial Networks (GANs) via Automatically Generated Image Galleries
Enhao Zhang and Nikola Banovic
In Proc. CHI '21. ACM, New York, NY, USA, Article 76, 15 pages.
Generative Adversarial Networks (GANs) can automatically generate quality images from learned model parameters. However, it remains challenging to explore and objectively assess the quality of all possible images generated using a GAN. Currently, model creators evaluate their GANs via tedious visual examination of generated images sampled from narrow prior probability distributions on model parameters. Here, we introduce an interactive method to explore and sample quality images from GANs. Our first two user studies showed that participants can use the tool to explore a GAN and select quality images. Our third user study showed that images sampled from a posterior probability distribution using a Markov Chain Monte Carlo (MCMC) method on parameters of images collected in our first study resulted in on average higher quality and more diverse images than existing baselines. Our work enables principled qualitative GAN exploration and evaluation.
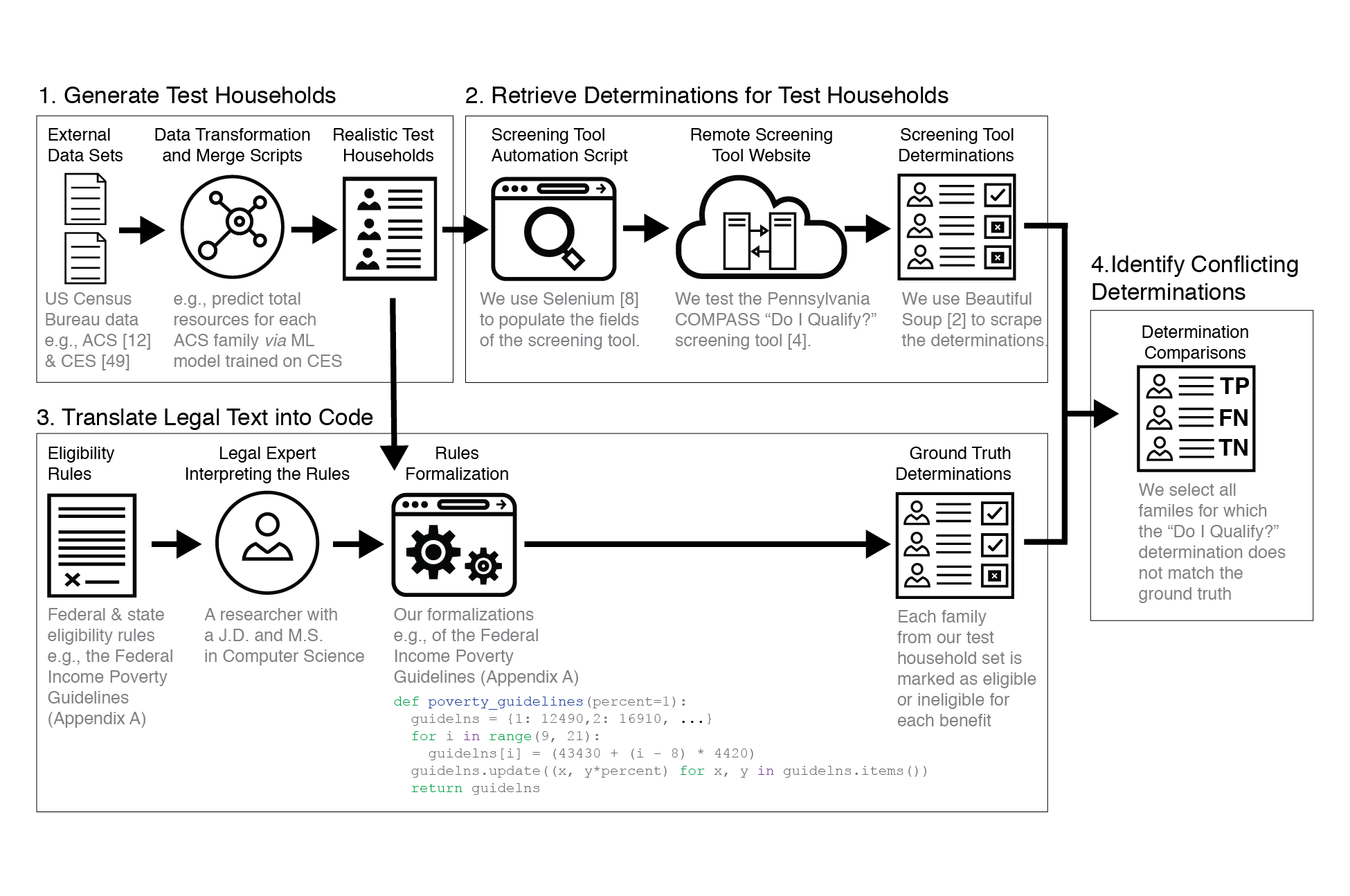
Exposing Error in Poverty Management Technology: A Method for Auditing Government Benefits Screening Tools
Nel Escher and Nikola Banovic
PACM HCI 4, CSCW1, Article 64 (May 2020) (CSCW 2020). ACM, New York, NY, USA, 20 pages.
Public benefits programs help people afford necessities like food, housing, and healthcare. In the US, such programs are means-tested: applicants must complete long forms to prove financial distress before receiving aid. Online benefits screening tools provide a gloss of such forms, advising households about their eligibility prior to completing full applications. If incorrectly implemented, screening tools may discourage qualified households from applying for benefits. Unfortunately, errors in screening tools are difficult to detect because they surface one at a time and difficult to contest because unofficial determinations do not generate a paper trail. We introduce a method for auditing such tools in four steps: 1) generate test households, 2) automatically populate screening questions with household information and retrieve determinations, 3) translate eligibility guidelines into computer code to generate ground truth determinations, and 4) identify conflicting determinations to detect errors. We illustrated our method on a real screening tool with households modeled from census data. Our method exposed major errors with corresponding examples to reproduce them. Our work provides a necessary corrective to an already arduous benefits application process.
Ethical and Responsible Computing

Ludification as a Lens for Algorithmic Management: A Case Study of Gig-Workers’ Experiences of Ambiguity in Instacart Work
Divya Ramesh, Caitlin Henning, Nel Escher, Haiyi Zhu, Min Kyung Lee,
and Nikola Banovic
(To appear) In Proc. DIS '23. ACM, New York, NY, USA, 14 pages.
On-demand work platforms are attractive alternatives to traditional employment arrangements. However, several questions around employment classification, compensation, data privacy, and equitable outcomes remain open. Fraught regulatory debates are compounded by the abilities of algorithmic management to structure different forms of platform-worker relationships. Understanding the conditions of algorithmic management that result in these variations could point us towards better worker futures. In this work, we studied the platform-worker relationships in Instacart work through the accounts of its workers. From a qualitative analysis of 400 Reddit posts by Instacart's workers, we identified sources of ambiguity that gave rise to open-ended experiences for workers. Ambiguities supplemented gamification mechanisms to regulate worker behaviors. Yet, they also generated positive affective experiences for workers and enabled their playful participation in the Reddit community. We propose the frame of~\textit{ludification} to explain these seemingly contradicting findings and conclude with implications for accountability in on-demand work platforms.
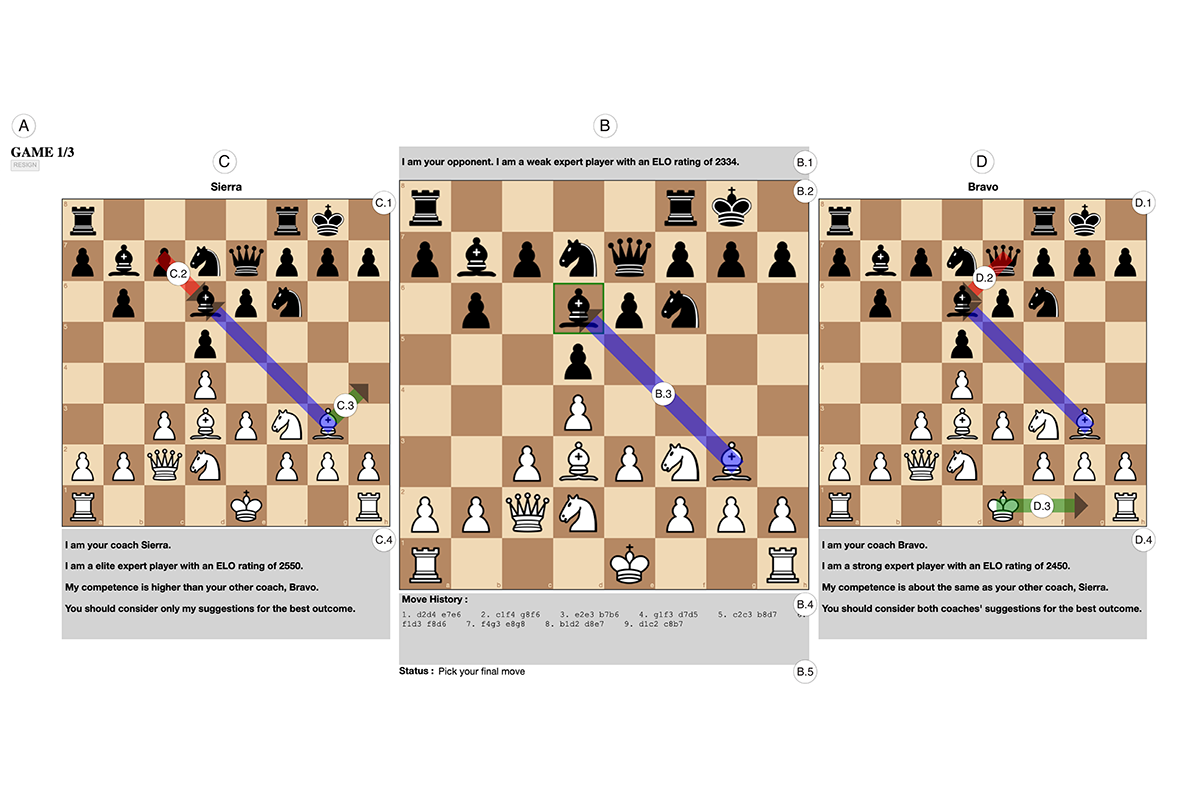
Being Trustworthy is Not Enough: How Untrustworthy Artificial Intelligence (AI) Can Deceive the End-Users and Gain Their Trust
Nikola Banovic, Zhuoran Yang, Aditya Ramesh, and Alice Liu
PACM HCI 7, CSCW1, Article 27 (April 2023), 17 pages.
Trustworthy Artificial Intelligence (AI) is characterized, among other things, by: 1) competence, 2) transparency, and 3) fairness. However, end-users may fail to recognize incompetent AI, allowing untrustworthy AI to exaggerate its competence under the guise of transparency to gain unfair advantage over other trustworthy AI. Here, we conducted an experiment with 120 participants to test if untrustworthy AI can deceive end-users to gain their trust. Participants interacted with two AI-based chess engines, trustworthy (competent, fair) and untrustworthy (incompetent, unfair), that coached participants by suggesting chess moves in three games against another engine opponent. We varied coaches' transparency about their competence (with the untrustworthy one always exaggerating its competence). We quantified and objectively measured participants' trust based on how often participants relied on coaches' move recommendations. Participants showed inability to assess AI competence by misplacing their trust with the untrustworthy AI, confirming its ability to deceive. Our work calls for design of interactions to help end-users assess AI trustworthiness.
